##一、前言 ###历史背景 先说明一下背景,目前我们公司使用的 MQ 主要是 RabbitMQ 和 Kafka,RabbitMQ 主要是业务场景居多,Kafka 则多用于数据同步、日志收集等场景;在使用 MQ 上面我们有几个痛点:
- 各业务线维护自己的 MQ 实例集群,比较混乱,无法统一维护,资源使用也很浪费;
- RabbitMQ 性能和稳定性方面不满足要求;
- 性能问题,并且无法横向扩容,只能升级硬件规格;
- 稳定性问题,因为设计上是内存型队列,抗堆积能力差,容易引发内存问题导致宕机;
- 维护复杂,不支持消息积压、回溯,不支持查询历史消息,运维界面复杂; 另外,对于一些常用的消息队列功能特性,比如延时/定时消息、事务消息(最终一致性),目前业务也是用自己的方式实现,缺少统一的解决方案;
需求
基于以上几点,笔者所在的基础架构组就想要做一个统一消息服务,期望能解决上述痛点,对这个消息服务的需求我稍微做了下总结:
功能型需求
- 控制平面
- 支持 MQ集群、Topic 的统一运维管理
- 支持 多业务线多业务隔离需求(多租户)
- 丰富的监控指标
- 支持 延时/定时 消息
- 支持 顺序性 消息
- 支持 消息积压、回溯;
- 支持 消息重试 & 死信队列;
- …
非功能型需求
- 性能
- 吞吐量(和 Kafka 同个数量级)
- 端到端 延迟(和 Kafka 同个数量级)
- 对于多 topic 有较好的支持
- 服务可用性
- 故障切换
- 横向扩容
- 数据可靠性
- 支持多副本和灵活的消息持久策略,能支持消息不丢;
- … ## 二、MQ 选型对比 集团当前使用情况
- RabbitMQ ,版本:3.7.17
- Kafka,版本:2.3.0 其他MQ 对比版本
- pulsar,版本:2.8.0
- RocketMQ,版本:4.X 对比项
- 功能特性
- 性能 & 可用性
- 运维
- 管理界面
- 部署方式 & 机器消耗
- 社区支持 & 文档 & 学习 ### 2.1 功能维度 功能项 | RabbitMQ|RocketMQ |Kafka|Pulsar —|—|—|—|—| 优先级队列 |✅ |❌|❌|❎可以自己封装 延迟/定时消息 | ✅|✅开源版本功能有限|❌| ✅ 消息重试| ❌|✅|❌|✅ 死信队列 | ✅|✅|❌|✅ 消息顺序 | ❌|✅|✅|✅ 消息过滤 | ❌|✅|❌|✅ 消息回溯 | ❌|✅|✅|✅ 消息积压 | ✅|✅|✅|✅ 事务消息(For Exactly Once) | ❌|❌|✅|✅ 事务消息(For 最终一致性) | ❌|✅|❌|❌ 流量控制 | ❌|✅|✅|✅ 多租户 | ✅|❌|❌|✅ 多语言 | ✅|✅|✅|✅ 协议支持 | RabbitMQ基于AMQP协议实现,同时支持MQTT、STOMP等协议。|私有|私有|私有协议,但通过扩展 ProxyHandler 可以兼容支持AMQP、MQTT、Kafka等协议(社区有专门的子项目支持这一块)
2.2 高性能 & 高可用
高可用性
RabbitMQ
RabbitMQ 依赖「镜像队列」功能实现镜像集群:每个RabbitMQ节点既保存有队列相同的元数据,又保存有队列实际的消息数据。 任一节点宕机,不影响消息在其他节点上进行消费。缺点在于:
- 性能开销非常大,因为要同步消息到对应的节点,这个会造成网络之间的数据量的频繁交互,对于网络带宽的消耗和压力都是比较重的
- 扩展性差,rabbitMQ是集群,但不是分布式的,所以当某个Queue负载过重,并不能通过新增节点来缓解压力,因为所有节点上的数据都是相同的,这样就没办法进行扩展了
- 镜像队列不是负载均衡,因为每个操作在所有节点都要做一遍。镜像队列无法提升消息的传输效率,或者更进一步说,由于镜像队列会在不同节点之间进行同步,会消耗消息的传输效率。
RocketMQ
RocketMQ 集群包含两个组件:NameServer集群、Broker集群。每台NameServer 机器都拥有所有的路由信息,包括所有的 Broker 节点信息、数据信息等 ,这样只要有一台 NameServer 存活就不会影响系统的稳定性。 若 Master Broker 挂掉,RocketMQ 4.5 版本之前,是人工运维,通过人手工切换 Master Broker,RocketMQ4.5 之后,通过 Dledger 技术以及 Raft 协议进行 leader 选主。整个过程很快,大概十几秒或者几十秒就能完成切换动作,全自动的将 Slave Broker 选为Master broker 对外提供服务,实现高可用模式;
Kafka
Kafka 集群包含两个组件:Zookeeper 集群、Broker集群。 一般 3 台以上就可以组成一个可用的 ZooKeeper 集群,只要集群中存在超过一半的机器能够正常工作,那么整个集群就能够正常对外服务; Kafka 高可用依赖于 副本机制 + ISR + Leader (基于 zk); Kafka 扩容非常麻烦,需要对分区进行手动 rebalance,
- 分区重分配主要是对主题数据进行 Broker 间的迁移,因此会占用集群的带宽资源;
- 分区重分配会改变分区 Leader 所在的 Broker,因此会影响客户端。
Pulsar
Pulsar 集群包含三个组件:Zookeeper 集群、Broker集群、BookKeeper 集群。 一般 3 台以上就可以组成一个可用的 ZooKeeper 集群,只要集群中存在超过一半的机器能够正常工作,那么整个集群就能够正常对外服务; Broker 集群中的各个broker 是无状态的,如果拥有某个Topic的Broker崩溃,则将该Topic立即重新分配给另一个Broker。当发生 Topic 的迁移时,Pulsar 只是将所有权从一个 Broker 转移到另一个 Broker,在这个过程中,不会有任何数据复制发生。 Broker 的无状态性质使动态分配成为可能,因此可以根据使用情况快速扩展或收缩集群。 Bookeeper 集群包含一组Bookies节点,一个Topic由多个Ledger构成,一个Ledger由一个或多个Fragment组成,每个Fragment有多个条目Entry组成,每个Entry上包含的就是消息Message。Fragments分布在Bookie集群中,跨多个Bookies带状分布。存储可以单独扩展。如果存储是瓶颈,那么只需要添加更多的Bookies,他们会自动承担负载,不需要Rebalance。当Bookie不可用时,自动恢复模式将自动进行数据重新复制到其他的Bookies。 此外,BookKeeper 通过 Quorum Vote 的方式来实现数据的一致性,跟 Master/Slave 模式不同,BookKeeper 中每个节点也是对等的,对一份数据会并发地同时写入指定数目的存储节点。对等的存储节点,保证了多个备份可以被并发访问;也保证了存储中即使只有一份数据可用,也可以对外提供服务。
总结
选项 |RabbitMQ | RocketMQ |Kafka |pulsar —|—|—|—|—| end-to-end latency|(负载低的情况)最低|低|低|较低 TPS |低|高|高|高 高可用性 |差|好|好|极好 集群扩展能力 |差,集群无法增加性能|好|好|极好
pulsar 性能对比参考文章:
Benchmarking Kafka vs. Pulsar vs. RabbitMQ: Which is Fastest? (confluent.io)<https://www.confluent.io/blog/kafka-fastest-messaging-system/?utm_medium=sem&utm_source=google&utm_campaign=ch.sem_br.nonbrand_tp.prs_tgt.kafka_mt.mbm_rgn.apac_lng.eng_dv.all_con.kafka-pulsar&utm_term=%2Bkafka%2Bpulsar&creative=&device=c&placement=&gclid=Cj0KCQjwvO2IBhCzARIsALw3ASp_epmMFz7Yc1n5HwOn6bmTbzvx4KQGruoVrkeL043SgAVNBBy_Y-gaAoOnEALw_wcB#latency-results>
Pulsar和Kafka基准测试:Pulsar性能精准解析(完整版)<https://mp.weixin.qq.com/s?__biz=MzUyMjkzMjA1Ng==&mid=2247486295&idx=1&sn=4c755520a34d3b18949c48a718fd0bd9&scene=21#wechat_redirect>
2.3 运维
- 管理界面
- 部署方式 & 机器消耗
部署方式 & 机器消耗
完整搭建一个三节点的性能最优的集群,需要多少台机器 RabbitMQ 集群部署时,依赖「镜像队列」实现高可用,需要一个主队列(master)节点,两个从队列(slave)节点,即需要三台机器; RockerMQ 部署一个RocketMQ Dledger集群(包含一主两从),部署时最少需要三台机器;最多需要六台机器(三台用于NameServer集群,三台用于broker集群); Kafka 部署一个 Kafka 集群(包含一主两从),部署时最少需要三台机器;最多需要六台机器(三台用于ZK集群,三台用于broker集群); Pulsar 部署一个Pulsar 集群(包含一个ZooKeeper 集群(3 个 ZooKeeper 节点组成),一个bookie 集群(也称为 BookKeeper 集群,3 个 BookKeeper 节点组成),一个broker 集群(3 个 Pulsar 节点组成)),最少需要3台机器,官方建议6台机器,最多需要9台机器。
2.4 社区 & 文档 & 学习
选项|RabbitMQ |RocketMQ |Kafka |pulsar —|—|—|—|— 社区活跃度 |一般 |较活跃 |活跃 |活跃(< Kafka) 文档 |多 |民间多,但官方文档太一般了 |多 |民间少,但是官方文档非常好 学习 |渠道多 |渠道多 |渠道多 |官方文档 & 社区支持
三、选择 Pulsar 的理由
3.1 功能特性方面
除了基础的消息 pub/sub、消息积压、消息回溯、分区队列以外,下面的 pulsar 功能特性吸引了我们:
延时消息
Pulsar 2.4.0 之后引入的延迟消息投递的特性,并且可以精确指定延迟投递的时间。延迟消息的使用场景十分广泛,也是我们在规划统一消息服务的时候想要支持的,原生支持相当于节省了我们开发这块功能的时间。
多租户 & 命名空间
原先我们 RabbitMQ 集群使用情况是,每条业务线分配一个RabbitMQ 集群,不同的应用分配对应的 namespace,这种资源使用方式很容易浪费并且难以维护。 Pulsar 可以有多个租户,这些租户可以有多个命名空间,租户可以对应我们每条业务线,应用可以对应到 namespace。将来我们可以只使用一个Pulsar集群就能处理业务线的多租户问题。并且 Pulsar 还支持对配置每个命名空间的访问控制、配额、速率限制等,虽然我们初期不打算对资源做限制,但是这方面功能对以后业务线资源调控的长期规划提供了基础技术支持;
Pulsar Functions
Pulsar 原生支持功能即服务(FaaS),就和 Amazon Lambda 一样,可以实时分析、聚合或汇总实时数据流。截至目前,Pulsar Functions 支持 Java、 Python 和 Go 语言,其他语言将在以后的版本中陆续得到支持。
Pulsar Functions 的用户案例包括基于内容的路由(content based routing)、聚合、消息格式化、消息清洗等。这个功能可以扩展出来很多业务实践场景。
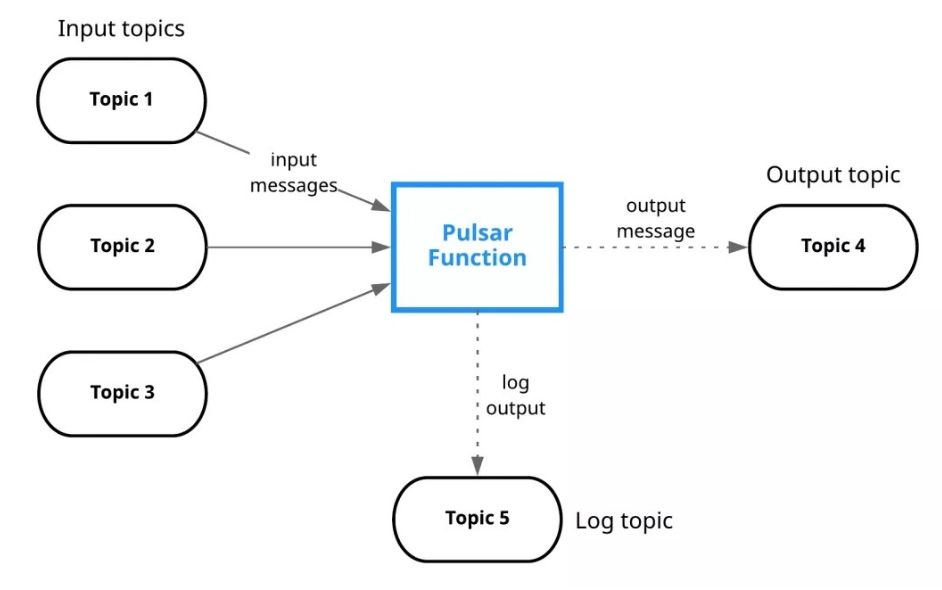
Topic 数量
Pulsar 可以支持百万级别 Topic 数量的扩展,同时还能一直保持良好的性能。Topic 的伸缩性取决于它的内部组织和存储方式。Pulsar 的数据保存在 bookie (BookKeeper 服务器)上,处于写状态的不同 Topic 的消息,在内存中排序,最终聚合保存到大文件中,在 Bookie 中需要更少的文件句柄。另一方面 Bookie 的 IO 更少依赖于文件系统的 Pagecache,Pulsar 也因此能够支持大量的主题。
消费模型
Pulsar 支持三种消费模型:Exclusive、Shared 和Failover。
- Exclusive (独享):一个 Topic 只能被一个消费者消费。Pulsar 默认使用这种模式。
- Shared(共享):共享模式,多个消费者可以连接到同一个 Topic,消息依次分发给消费者。当一个消费者宕机或者主动断开连接时,那么分发给这个消费者的未确认(ack)的消息会得到重新调度,分发给其他消费者。
- Failover (灾备):一个订阅同时只有一个消费者,可以有多个备份消费者。一旦主消费者故障,则备份消费者接管。不会出现同时有两个活跃的消费者。
Exclusive和Failover订阅,仅允许一个消费者来使用和消费每个订阅的Topic。这两种模式都按 Topic 分区顺序使用消息。它们最适用于需要严格消息顺序的流(Stream)用例。 Shared 允许每个主题分区有多个消费者。同一个订阅中的每个消费者仅接收Topic分区的一部分消息。Shared最适用于不需要保证消息顺序队列(Queue)的使用模式,并且可以按照需要任意扩展消费者的数量 还有一个 key_shared 模式,key_sticky的工作方式,场景太少
3.2 性能 & 稳定性方面
吞吐量 和 端到端延时 表现
虽然我们暂时没有实际部署标准规格的 Pulsar 集群做性能测试,但是从 StreamNative 官方给出的 《Pulsar和Kafka基准测试:Pulsar性能精准解析》 中可以看出来,Pulsar 的性能表现完全可以在提供较高吞吐量的同时保持较低的延迟,符合我们的性能需要。
水平扩容
由于 Pulsar 的存储设计基于分片,Pulsar 把主题分区划分为更小的块,称其为分片。每个分片都作为 Apache BookKeeper ledger 来存储,这样构成分区的分片集合分布在 Apache BookKeeper 集群中。这样设计方便我们管理容量和水平扩展,并且满足高吞吐量的需求。
- 容量管理简单:主题分区的容量可以扩展至整个 BookKeeper 集群的容量,不受单个节点容量的限制。
- 扩容简单:扩容无需重新平衡或复制数据。添加新存储节点时,新节点仅用于新分片或其副本,Pulsar 自动平衡分片分布和集群中的流量。
- 高吞吐:写入流量分布在存储层中,不会出现分区写入争用单个节点资源的情况。
数据持久化&一致性保证
简单来说可以保证写入响应成功之后的数据不丢 Pulsar 引入了 Apache BookKeeper 作为存储层,Apache BookKeeper 提供的三个核心特性:I/O 分离、并行复制和容易理解的一致性模型。它们能够很好地满足我们对于持久化、多副本和一致性的要求。Pulsar Broker 本身是无状态的,所以数据的持久化、一致性保证是由 BookKeeper 保证的。 至于BookKeeper 如何保证的,由于篇幅原因不在本文介绍,有兴趣可以看看这篇 【年度案例】Twitter高性能分布式日志系统架构解析
跨地域复制
Pulsar 应该是目前开源 MQ 中唯一自带跨地域复制机制(Geo-Replication)功能的,Pulsar 在设计之初就考虑到了这个特性。虽然目前我们的体量还没有到设计异地多活或者多机房灾备方案的地步,但随着公司后期发展,这一块内容肯定是会被提上日程。
3.3 业务侧接入难度方面
因为定位是一个统一的消息服务,并且旨在替换到集团原先的 RabbitMQ 集群,甚至说在后期稳定的时候去替换部分 Kafka 的场景。所以肯定会涉及到旧应用的改造接入。比如原先 A 服务是接 RabbitMQ的,B 服务是接 Kafka 的,如何让他们以最低的成本进行替换呢? 如果让每个应用都进行代码重写,对于一个在高速发展的业务来说肯定是不可接收的,然而 Pulsar 生态中包含了协议代理的子项目 KoP(Kafka on Pulsar)和 AoP(AMQP on Pulsar) 就可以解决我们痛点。 通过扩展 ProxyHandler可以开发不同的协议插件,将 AoP 和 KoP的协议处理插件添加到现有 Pulsar 集群后,Pulsar 就支持原生 AMQP 协议和 Kafka 协议了。应用可以不需要任何代码就可以迁移到 Pulsar 上面来。 协议兼容的方式是对业务最友好的接入方式,但是这意味很高的开发成本,但是 Puslar 开源生态中自带了这一部分的组件着实让人欣喜。
除了协议代理插件以外,Puslar I/O 组件也支持从第三方数据源拷贝数据到Pulsar,可以解决我们迁移时的数据复制问题。
3.4 运维难度方面
监控告警
我们目前的监控告警是 基于 Prometheus + Grafana 的体系,Pulsar 提供丰富的 Prometheus 指标信息输出,我们可以这些指标信息来做好Pulsar的监控报警。grafana 面板市场上也有 Pulsar 的 dashboard template。 监控告警的实践感兴趣可以阅读这篇文章:Apache Pulsar在智联招聘的实践 – 从消息队列到基于Apache Pulsar的事件中心
集群管理运维
Pulsar Manager 提供了友好的界面管理工具,可以对集群、存储、租户、名称空间、Topic 等方面的监控和管理,底层基于 Pulsar 提供的 admin api;使用 admin api 可以通过 admin-cli 工具(命令行)、REST API、客户端SDK 等等的方式,非常方便内部系统做定制化开发。
3.5 研发投入
我们目前能投入到这块人力很少,所以我们刚开始的目标就是尽可能少的对 MQ 产品本身做定制化改造,一个功能特性齐全,生态完整,社区活跃的MQ能够极大减少我们在这方面的投入,让我们更专注于统一消息服务的控制平面层的开发和内部基础平台的能力对接、业务侧接入标准化流程的制定、MQ 产品的运维等方面的工作上面;